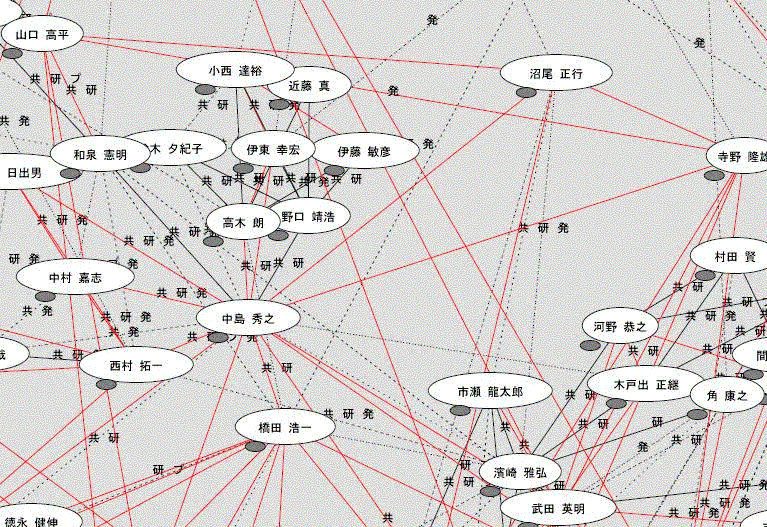
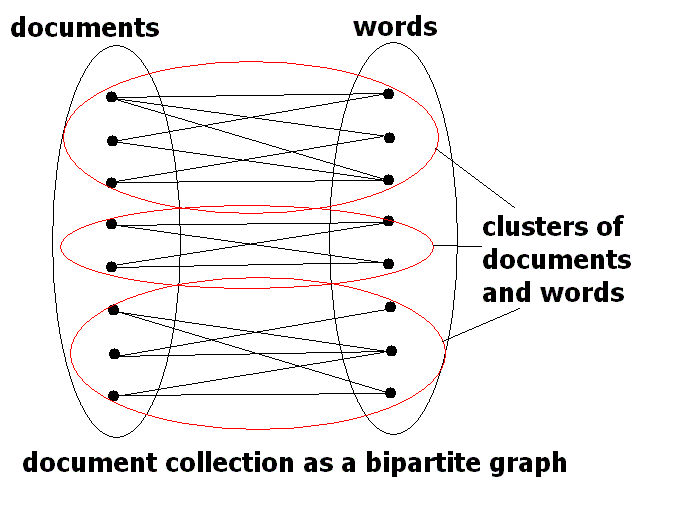
Table 1 : The top 10 keywords and the number of people in each group
| Group number |
The top 10 keywords |
The number of people |
| #1 |
"TVCF" |
1 |
| #2 |
"edu-tainment" |
2 |
| #3 |
"wearable", "Web service orchestration", "semantics", "MGTP", "demand bus", "sensor network", "radius of curvature", "POMDPs", "multiple categories", "grid environment" |
21 |
| #4 |
"multiple handicaps", "story structure element", "appreciation process", "metaphor", "autistic child", "recycle system", "body language", "hypertext", "the number of steps taken", "kinesthesia" |
9 |
| #5 |
"discourse", "narrative discourse theory", "sound animation" |
2 |
| #6 |
"mutuality", "dialogue management", "conversation", "behavior and intelligence", "design knowledge description", "dynamic adaptation", "parallel recognition", "web adaptation", "learning environment", "object recogntion" |
60 |
| #7 |
"event space", "pen touch", "Robovie", "punin" |
0 |
| #8 |
"rhetoric", "poetic", "poetic effect", "software management" |
7 |
| #9 |
"interaction", "cooperative action", "autonomos movement", "scheduling", "real world information", "object detection", "data mining", "robotics","robust","mining" |
70 |
| #10 |
"corpus", "intelligent learning support enviroment", "dialogue context", "learning support system", "dialogue strategy", "unknown word", "concept assciation", "learning contents", "concept cooccur dictionary", "inheritance support environment" |
28 |